P-value의 P는 [Probability]에서 나온 단어인데요. 그렇다면 "무슨"확률을 뜻하는 걸까요? P-value는 귀무가설($H_0$, null hypothesis)이 사실일 때, 데이터에서 관찰된 값, 혹은 그 이상의 결과를 관찰할 확률입니다. 이건 또 무슨 말일까요!
초콜릿 m&m 다들 아시죠? 시중에 나와있는 1.69 Ounce - 봉지에 있는 초콜릿이 평균 45, 표준편차 3.5으로 가정합니다(모집단(Population)).우리는 이 가정, 즉 귀무가설($H_0$) 이 맞는지 확인해보고 싶어요. 그래서 슈퍼마켓에 가서 20 봉지를 삽니다! 그리고는 확인해 봤는데, 평균을 내어보니 46.8이 나왔어요. 음? 평균이 45 정도로 기대됐는데, 46.8이라니, 혹시 m&m에 원래 45개 보다 더 많이 들었나? 아니면 내가 단지 운이 좋아서 기대 평균보다 조금 더 많은 초콜릿 봉지를 골랐나? 궁금해집니다.
그래서, 시중에 나와있는 모든 m&m 1.69 Ounce 봉지에 평균 45개의 초콜릿이 들었다는 가정 하에, 내가 산 초콜릿 각각의 봉지, 즉 모집단에서 추출한 표본집단에서 46.8개 혹은 그 이상이 들어있을 확률이 얼마나 될지를 계산해보고 싶어요.
이 때 계산하는 확률 값을 바로 P-Value라고 합니다.
그렇다면 초콜릿이 46.8개 이상을 들어 있는 확률은 어떻게 계산을 할까?
가설 검증(Hyptheses Test)을 할 때, 샘플 크기와 예측 변수 수의 조합에 따라 통계 검정(Statistical test)을 이용하여 검정 통계량(test statistic)을 구합니다. 통계 검정 종류의 예로는 Z-test, T-test, Anova, Chi-squared test 등이 있는데요, 이 통계 검정의 종류에 따라 Test statistic의 값이 정해질 수 있습니다. 예를 들면 정규분포에서 설명했던 Z-value (Z-score) 그리고 t-value, F-value, $\chi^2$value 가 있습니다. 우리는 여기서 1봉지당 초콜릿 수가 정규분포를 따른다고 가정합니다.
$H_0$(귀무가설 - Null Hypothesis): $\mu$ = 45 (m&m 한 봉지에 평균 초콜릿 45개가 들어있다.)
$H_1$(대립가설 - Alternative Hypothesis): $\mu$ > 45 (m&m 한 봉지에 평균 초콜릿이 45개 보다 많이 들어있다.)
정규분포를 가정하였으므로, Z-value를 구하는 공식을 사용합니다:
- 모집단 평균(Population mean($\mu$)): 45
- 모집단 표준편차(Population standard deviation ($\sigma$)): 3.5
- 표본 크기 (sample size (n)): 20
- 표본 평균(sample mean ($\bar{x}$)): 46.8
$$Z = \frac{\bar{x} - \mu}{\frac{\sigma}{\sqrt(n)}} = \frac{46.8-45}{\frac{3.5}{\sqrt{20}}}= 2.299$$
표준화는 어떻게 하는지에 대해 설명할 때 우리가 $\sigma$, 즉 모집단의 표준편차로 나눈 기억이 있으실거에요. 그런데 여기서 우리가 표준화하는 대상은 샘플, 즉 표본집단이므로, 모집단의 표준편차가 아닌, 각 표본의 평균들의 표준편차(=표준오차)를 단위로($\frac{\sigma}{\sqrt{n}}$) 표본집단의 평균이 모집단의 평균에서 얼마큼 떨어져 있는가를 계산합니다. 이에 대한 자세한 개념을 조만간 꼭 설명해야겠다 생각하며 일단 다음으로 넘어가겠습니다.
이를 그래프로 나타내면 다음과 같습니다. 제일 처음에 설명하였듯이, 관찰된 값, 혹은 그 이상의 결과를 관찰할 확률이 빨간 줄로 쳐진 구간이고, 이 면적을 계산하면 P-value가 됩니다.

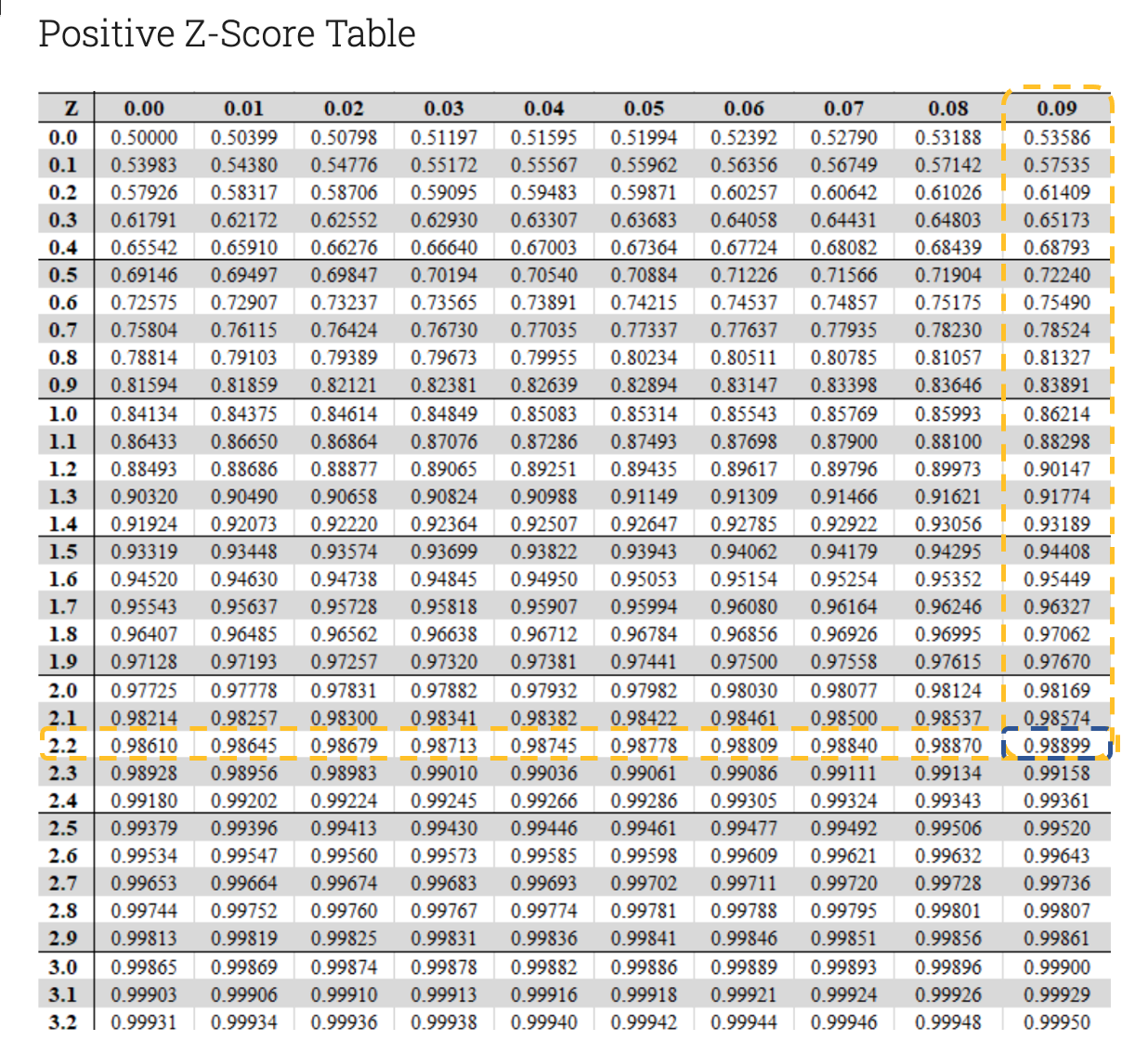
표준 정규분포표의 값을 이용하면 Z 라 2.29일 때 0.98899. 우리가 구하고자 하는 값은 2.29이상의 구간이므로
$$1-0.98899 = 0.01101$$
즉, P-value는 0.011 이 됩니다.
이렇게 직접 계산하지 않고 R로 바로 나타내고 싶으면 다음과 같이 [pnorm]을 이용할 수 있습니다.

20봉지의 초콜릿을 세어보고,
아직도 한 봉지당 평균 초콜릿이 45개라고 할 수 있을까?
우리가 사실 시중에 나와있는 모든 m&m 봉지에 들은 초콜릿 수를 세어서 평균을 내기란 사실 불가능합니다. 그리하여 일단 평균 초콜릿 수와 표준편차를 가정한 후, 우리가 실험 가능한 범위에서의 값을 추출하여, 우리가 처음 정한 가정이 받아들일 만 한가, 아닌가를 알아보는 값이 P-value입니다.
1봉 지당 평균 45개가 들어 있다고 가정하였는데, 20개의 표본에서 평균 초콜릿이 46.8 개 들어있다고 확인했습니다. 그런데 알고 보니, 평균이 45인 모분포에서는 46.8 이상을 관찰할 확률이 0.01, 즉 1% 정도밖에 되지 않는다는 겁니다. 모집단의 평균이 45일 때, 내가 확인한 결과인 46.8개 혹은 그보다 많은 초콜릿이 들어있는 상황이 100번 중 1번뿐이라는데, 우리는 우리가 샀던 20개의 봉지에서 확인을 하게 된 거죠. 우연이라기에는 관찰될 확률이 너무 낮은데도 우리의 샘플에서 관찰이 된 겁니다. 그러므로 아무래도 모집단의 평균이 45가 아닐 수도 있다는 생각을 해볼 수 있습니다. 이를 우리는 귀무가설을 기각한다고 합니다.
이때, 귀무가설이 틀렸다는 뜻이 아니라는 것을 짚고 넘어가야 하는데요. 귀무가설이 맞다고 하기에는, 귀무가설이 맞을 때 아주 작은 확률로 일어날 수 있는 상황이 나의 샘플에서 도출되었으므로 (극단적으로는 귀무가설이 맞다면 일어나지 말아야 할 상황이 내 샘플에서 도출되었으므로), 귀무가설이 맞다고 하기에는 확신하기가 어렵다는 뜻으로 해석합니다.
그래서, 언제 기각하는 것이 적당할까?
P값이 얼마라면 귀무가설을 기각해도 좋은지를 결정하는 것이 유의 수준 입니다 . 즉 P값이 유의 수준 미만이면 드물게 일어나지 않는 상황이 일어나고 있다 (즉 귀무가설을 확신하기 어렵다)라고 보는 것인데요, 유의 수준은 관례적으로 0.05(5%) 로 설정되어 있습니다.
정규분포를 보면 아시겠지만, 평균 $\mu$, 표준편차 $\sigma$의 정규분포에 따른 확률변수가 $\mu \pm 2\sigma$일 때 95%이므로, 평균으로부터 표준편차 2배 이상 벗어날 확률, 즉 $\mu \pm 2\sigma$ 범위 밖의 값을 취할 확률이 5% 정도로 알기 쉽다는 이유죠. 하지만 0.05라는 것은 그저 관습적으로 정해져 있는 것으로, 최근에는 유의 수준을 낮추는 편이 좋은 것은 아닐까 하는 논의도 이루어지고 있다고 합니다.
2023.04.04 - [Stats101] - 표준화 및 표준 정규 분포(Standard Normal Distribution)
표준화 및 표준 정규 분포(Standard Normal Distribution)
정규분포(Normal Distribution)에서 잠시 언급하였듯, 정규 분포를 따르는 자연 현상이나 사회 현상은 무궁무진합니다. 그만큼 정규분포를 구성하는 평균과 분산이 다양하기 때문에, 세상의 모든 정
minitistics.tistory.com
2023.04.16 - [Stats101] - 표준오차, 표본오차와 신뢰구간
표준오차, 표본오차와 신뢰구간
앞서 표본 표준편차에는 왜 n-1을 할까? 에서 표본 집단과 표본 평균집단이 다르다는 점을 설명하였는데요, 표준편차와 표본오차가 헷갈릴 수 있을 것 같아 잠시 짚고 넘어가보겠습니다. (1)표준
minitistics.tistory.com
'Stats101' 카테고리의 다른 글
| 분산과 표준편차 (0) | 2023.04.09 |
|---|---|
| 귀무가설, 대립가설 그리고 P-hacking (0) | 2023.04.07 |
| 표준화 및 표준 정규 분포(Standard Normal Distribution) (0) | 2023.04.04 |
| Box Plot과 Histogram을 이용한 데이터 비대칭 분별 (0) | 2023.04.03 |
| 평균값(Mean), 중앙값(Median), 최빈값(Mode) (0) | 2023.04.02 |




댓글