카이제곱(chi^2) 적합도 검정(Goodness of fit test)은 우리가 여태까지 배워온 t검정, 분산분석과 같은 가설검정입니다. 즉, 샘플을 기반으로 모집단 분포에 대한 결론을 도출하는데요, 카이 제곱의 적합도 테스트를 사용하여 모집단이 해당 분포를 따른다는 결론을 내릴 만큼 적합도가 충분히 좋은가의 여부를 테스트할 수 있습니다.
카이제곱 적합도 검정은 통계 모델이 일련의 관찰에 얼마나 잘 맞는지 알려줍니다. 적합도가 높으면 모델을 기반으로 예상되는 값이 관측값에 가깝고, 반대로 적합도가 낮으면 모델을 기반으로 예상되는 값이 관측값과 멀리 떨어져 있겠죠.
그렇다면 언제 카이제곱 적합도 검정을 사용할 수 있을까요?
- 범주형 변수: 하나의 범주형 변수에 대한 분포를 따르는지의 가설 검정이므로, 범주형 변수가 존재하거나, 번주형 변수로 변환이 가능해야 합니다.
- 독립성: 독립성은 이제 거의 진리와 다름 없죠! 표본은 모집단에서 무작위로 선택합니다.
- 최소 기대값: 각 그룹에는 최소 5개의 관측값이 예상되어야 합니다.
이제 카이제곱 검정을 실행하기 위해 우리가 p-value를 설명할 때에도 썼던 m&m으로 설명해볼게요.
2023.04.06 - [Stats101] - m&m 초콜릿으로 P-value 쉽게 이해하기
m&m 초콜릿으로 P-value 쉽게 이해하기
P-value의 P는 [Probability]에서 나온 단어인데요. 그렇다면 "무슨"확률을 뜻하는 걸까요? P-value는 귀무가설($H_0$, null hypothesis)이 사실일 때, 데이터에서 관찰된 값, 혹은 그 이상의 결과를 관찰할 확률
minitistics.tistory.com
어느 한 웹사이트에서 m&m 색상 분류를 게시하였는데, 이 때 초콜렛의 각 색상 분포는 다음과 같다고 가정 합니다.
| m&m 색 | 분포 |
| 파랑색 | 25% |
| 주황색 | 21% |
| 초록색 | 17% |
| 빨강색 | 14% |
| 노랑색 | 13% |
| 갈색 | 10% |
정말 그럴까요? 정말 파랑색이 가장 많고, 갈색이 가장 적을까? 너무 궁금하여 m&m 표본을 수집합니다. 우리가 p-value에서 m&m을 예시로 사용하면서 모평균이 45와 같다는 귀무가설을 기각하고 표본 평균 46.8로 45보다 많다고 결론을 내렸으므로, m&m 10봉지를 구입했다고 가정, 한 봉지당 평균 47개*10봉지 = 470개의 표본을 수집하였다고 해봅시다.
이 470개의 m&m을 색깔별로 분류해 보았더니, 다음과 같은 결과가 나왔습니다.
| m&m 색 | Observed (O) |
| 파랑색 | 110 |
| 주황색 | 105 |
| 초록색 | 85 |
| 빨강색 | 70 |
| 노랑색 | 55 |
| 갈색 | 45 |
우리의 표본이, 웹사이트에 나온 분포를 따르는지, 즉, 우리가 표본을 통해 알고자하는 모집단의 초콜릿 색이 정말 웹사이트에 나온 분포대로 존재할까? 를 이제부터 확인해보도록 하겠습니다. 가설을 먼저 세울텐데요, 카이제곱 검정(적합도 검정)은 다음과 같은 가설을 세울 수 있습니다.
귀무가설: 모집단이 특정 분포를 따른다.
대립가설: 모집단이 특정 분포를 따르지 않는다.
먼저, 카이제곱 적합도 검정 조건에 부합하는지 확인해보겠습니다.
1. 범주형 변수: 초콜릿의 각 색깔이 범주형 변수로 조건을 만족합니다.
2. 독립성: m&m을 무작위로 구매하여 수집한 표본이므로 독립성을 만족합니다.
3. 최소 기대값: 기댓값이 각 그룹에서 최소 5 이상이 관찰되었으므로 이 또한 만족합니다.
1. 카이제곱 검정 통계량 구하기
자, 그럼 이제 가설 검정을 위해 카이제곱 검정 통계량 (Chi-square test statistics)를 구해볼거에요.

여기서 O는 표본 관찰값(Observed), E는 기대값으로 각 관찰값과 기대값의 차이의 제곱합을 기대값으로 나누어 줍니다. 우리의 예시에서 기대값은 표본의 수 * 명시된 각 분포 % 로 아래와 같습니다.
| m&m 색 | Expected (E) |
| 파랑색 | 470*25%= 117.5 |
| 주황색 | 470*21%= 98.7 |
| 초록색 | 470*17%= 79.9 |
| 빨강색 | 470*14%= 65.8 |
| 노랑색 | 470*13%= 61.1 |
| 갈색 | 470*10%= 47 |
카이제곱 검정 통계량을 계산하면
| m&m 색 | Expected (E) |
| 파랑색 | (117.5-110)^2 = 56.25 |
| 주황색 | (98.7-105)^2 = 39.69 |
| 초록색 | (79.9-85)^2 = 26.01 |
| 빨강색 | (65.8-70)^2 = 17.64 |
| 노랑색 | (61.1-55)^2 = 37.21 |
| 갈색 | (47-45)^2 = 4 |
이는 곧

2. 카이제곱 임계값(Critical Value) 구하기
카이제곱 임계값을 구하기 전, 카이제곱 분포표를 사용하기 전 알아야 할 정보가 있습니다.
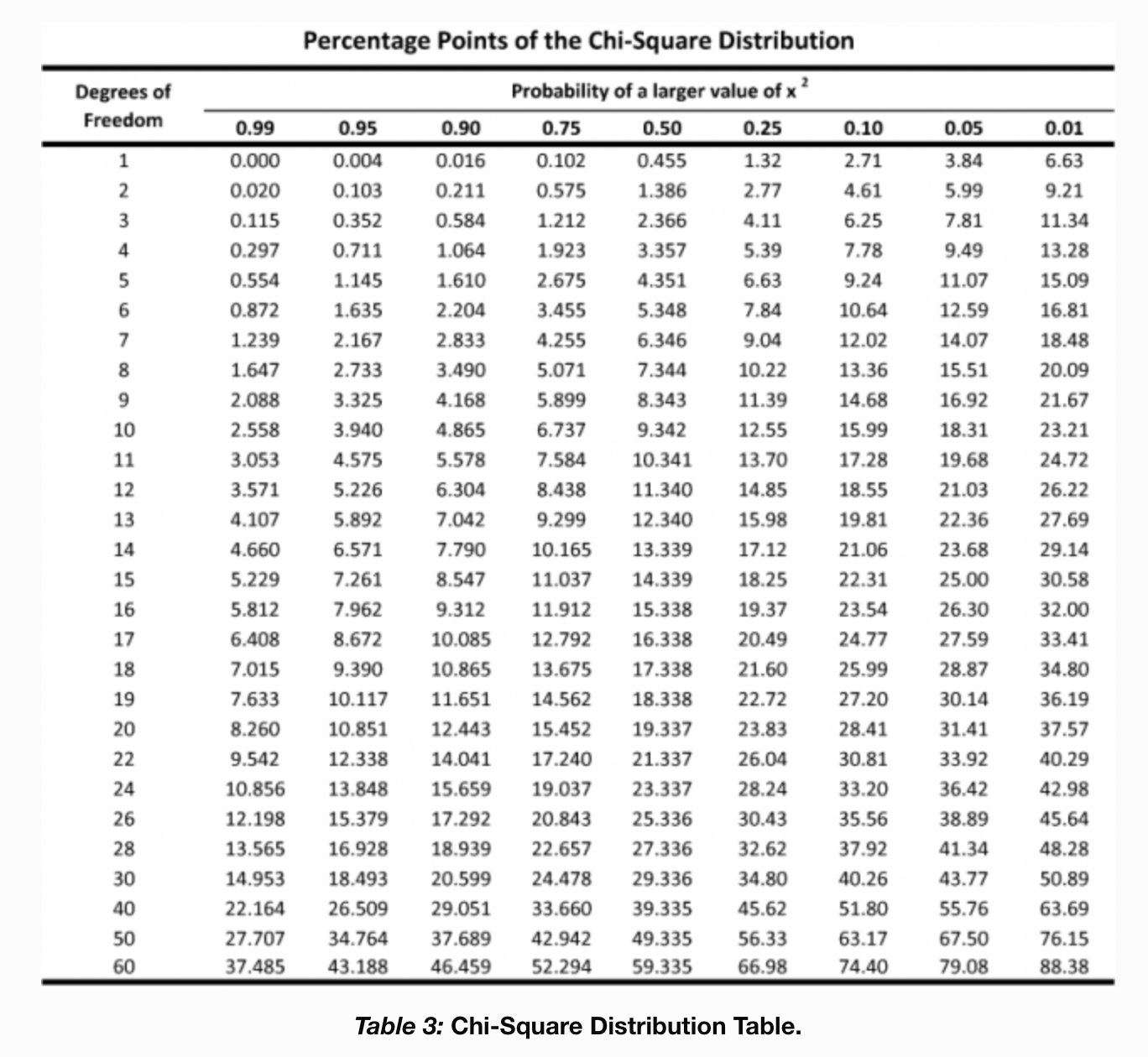
1. 자유도(df): 자유도는 그룹의 수에서 1을 뺀 값으로, 우리 m&m의 예시에서는 6가지 색이 있으므로 6-1 = 5가 됩니다.
2. 유의수준(α): 일반적으로 유의 수준을 0.05로 세웁니다.
2023.05.01 - [Stats101] - 자유도(Degrees of freedom)
자유도(Degrees of freedom)
우리가 앞서 t분포와 카이제곱 분포에 대해 정리하면서 자유도라는 개념을 접했는데요. 자유도(Degree of Freedom)는 말 그대로, 자유로운 정도를 나타냅니다. 도대체 데이터에서 자유로운 정도라니,
minitistics.tistory.com
카이제곱 분포표는 온라인 상에서 쉽게 찾아볼 수 있는데요, 위의 두 가지 정보를 토대로 아래에서 카이제곱 임계값을 찾아보면, 11.07이 됩니다. 나타내기로는,
$$\chi^2_{0.05, 5} = 11.07$$
1, 2번의 결과를 요약하면
카이제곱 검정 통계량 = 2.17
임계값 = 11.07
카이제곱 검정도 t검정과 비슷하게 결과를 해석하는데요, 카이제곱 검정 통계량이 임계값보다 크면 귀무가설을 기각하고 대립가설을 뒷받침할 충분한 근거가 있다고 보고, 그 반대의 경우는 귀무가설을 기각할 근거가 충분하지 않다고 봅니다.
우리가 지금 실행하고 있는 m&m 색깔 분포 테스트에서는 카이제곱 검정 통계량이 임계값에 비해 훨씬 작으므로, 귀무가설을 기각할 충분한 증거가 없다는 결론을 내릴 수 있습니다. 즉, m&m 모집단이 웹사이트에 나와있는 m&m 색깔 분포를 따를 것이라고 추정할 수 있습니다.
3. 카이제곱 검정 R에서 실행하기
카이제곱 검정을 R에서 실행하면 매우 간단해지는데요! 다음과 같습니다.

이미 데이터가 있다면, 단 한 줄로 가능합니다. 결과에 나온 카이제곱 검정 통계량 값은 2.1686으로 우리가 2번에서 매뉴얼로 계산한 값과 동일한 값임을 알 수 있습니다. 그리고 이에 대한 p-value는 0.8254 (>0.05)로 귀무가설을 기각할 증거가 충분하지 않다는 것을 나타냅니다.
다음편에서는, 카이제곱 검정의 또 다른 유형, 카이제곱 독립 검정(Chi-square Test of Independence)에 대해 알아보도록 하겠습니다.
'호주 데이터 분석가 > Stats101' 카테고리의 다른 글
| 카이제곱 분포(Chi-square distribution) (0) | 2023.04.30 |
|---|---|
| 카이제곱 독립성 검정 - Test of Independence (0) | 2023.04.29 |
| AIC(Akaike Information Criterion) (0) | 2023.04.25 |
| 이원 분산분석(Two-way ANOVA) (0) | 2023.04.24 |
| 일원 분산분석 (One-way ANOVA) (0) | 2023.04.23 |




댓글