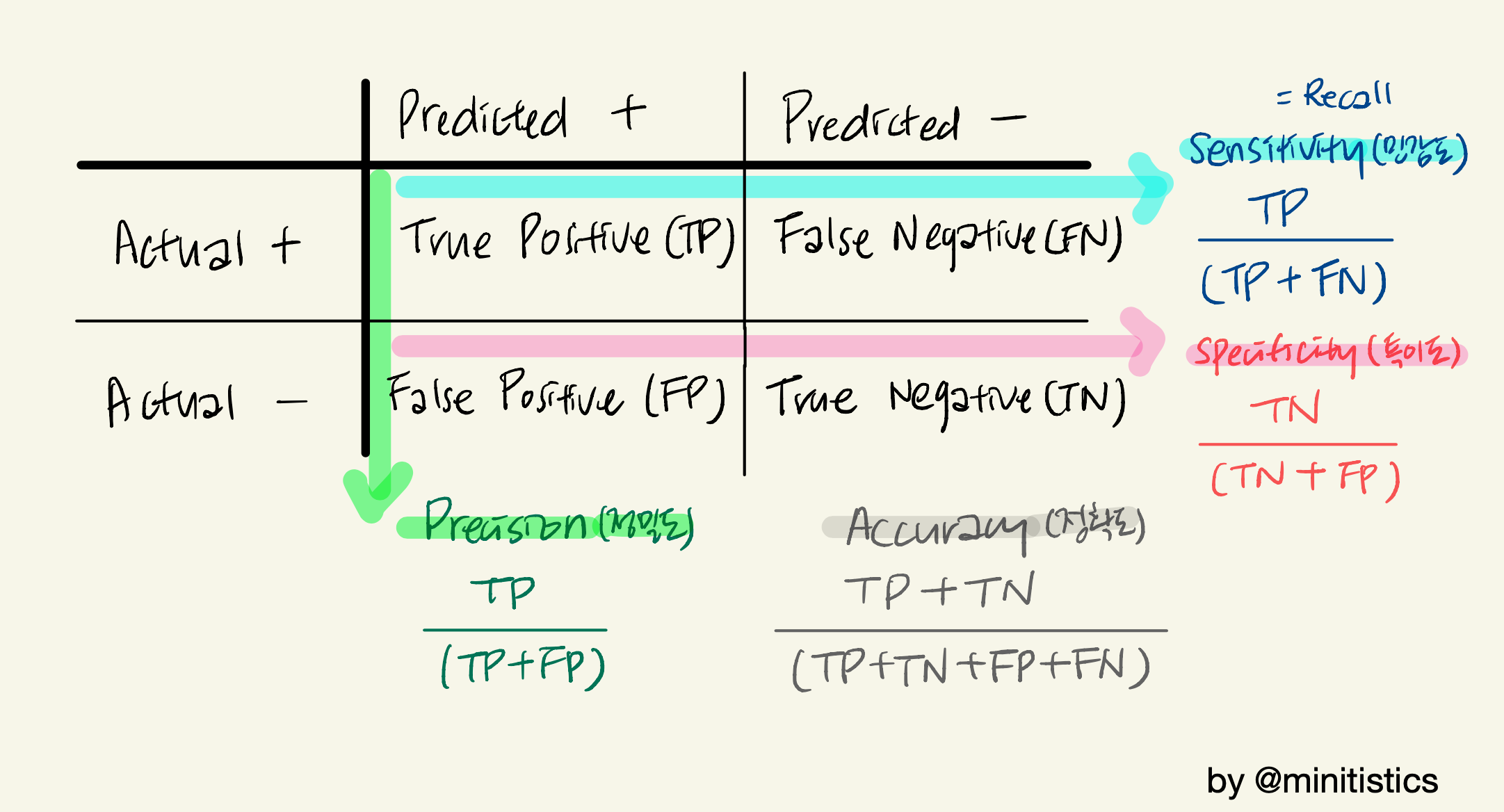
Confusion matixs는 통계적 분류를 하는데에 있어, 모델의 성과를 측정하기 위한 직관적인 도구입니다. 위의 도표와 같이 실제 값과 예측값의 정확도 뿐만 아니라, 민감도, 특이도, 정밀도 등을 검사하여 모델 성능의 실제 영향을 전달하기 위한 최고의 시각적 자료 중 하나가 되죠.
기본적으로 어떤 사안이 맞다, 아니다라는 베이스를 얼마나 올바르게 맞다, 아니다로 예측하였는지를 보여주는데요, 2X2 매트릭스가 나오는걸 알 수 있습니다. 한국어로는 진양성, 진음성, 위양성(가양성), 위음성(가음성)이라고도 하는데 이 포스팅에서는 TP, TN, FP, FN으로 풀어가겠습니다.
- True Positives (TP - 진양성): 맞는 것을 맞다고 예측한 경우.
- True negatives (TN - 진음성) : 맞는 것을 아니라고 예측한 경우.
- False positives (FP: Type 1 error - 위양성): 아닌 것을 맞다고 예측한 경우.
- False negatives (FN : Type 2 error - 위음성): 맞는 것을 아니라고 예측한 경우.
물론 언제나 올바르게 예측된 TP, TN가 많을수록 좋겠지만, 때에 따라서 FP와 FN이 똑같이 나쁜지 또는 둘 중 하나가 다른 것보다 나쁜지는 상황과 문제에 따라 다릅니다. 그래서 이 Confusion Matrix 를 통해 몇가지 식을 도출하여 모델을 평가할 수 있는데요, 그 예는 다음과 같습니다:
1. Accuracy(정확도)
2. Precision(정밀도)
3. Sensitivity(Recall)(민감도)
4. F1-Score
1. Accuracy(정확도)
정확도는 단순히 올바른 예측을 수행하는 빈도를 측정합니다. 즉, 정확한 예측 수와 총 예측 수 사이의 비율입니다.

| 예측 - 코로나 양성 | 예측 - 코로나 음성 | ||
| 코로나 양성 | TP - 85 | FN - 15 | 100 |
| 코로나 음성 | FP - 20 | TN - 80 | 100 |
| 105 | 95 | 200 |
여기서 우리가 모델을 통해서 하고 싶은 말은 "우리는 코로나를 82.5% 확률로 예측할 수 있다"입니다. 하지만 정확도 식을 보면, 코로나에 걸린 사람과 걸리지 않은 사람을 합하여 82.5%로 예측하는 것으로, 여전히 False Negative(FN)의 상황, 즉 코로나에 걸렸는데 걸리지 않았다고 하여 밖에 돌아다닐 수 있는 상황이 있는 것을 알 수 있습니다.
그리고 정확도는 메트릭스가 불균형일 때에는 사용하기 적합하지 않은데요, 설명을 위해, 좀 더 극단적으로 예시를 바꿔볼게요.
| 예측 - 코로나 양성 | 예측 - 코로나 음성 | ||
| 코로나 양성 | TP - 5 | FN - 15 | 100 |
| 코로나 음성 | FP - 20 | TN - 160 | 100 |
| 105 | 95 | 200 |
이 때 정확도는 165/200 = 82.5%로 위와 같지만, 이와 같은 집단의 경우에는 실제 코로나에 걸리지 않은 경우가 훨씬 많고, 실제 코로나에 걸린 경우는 아주 작은 수(5)일 뿐인데, 82.5%라는 정확도를 나타내고 있습니다. 이와같이 클래스가 상당히 불균형한 경우, 높은 정확도를 달성하기 위해 더 많은 그룹으로 전부 예측하여 몰아 넣으면 여전히 꽤 높은 정확도를 달성하게 됩니다. 모델이 사실상 의미가 없어지는 것이죠.
이렇게 정확도 자체가 언제나 모델에 대한 올바른 측정 기준이 될 수 없기 때문에, 우리가 알고 싶은 부분을 명확히 함으로써 다른 지표로 모델을 평가하기도 합니다.
코로나의 예로 들면, 전염성 바이러스의 확산을 막기 위해 다음 두가지 질문을 할 수 있습니다.
1) 양성이라 판단한 사람 중 실제 코로나에 걸린(양성) 사람은 얼마나 되는가
2) 얼마나 많은 양성 사례를 정확하게 예측할 수 있는가
이것이 바로 정밀도(Precision)와 민감도(Sensitivity, Recall)가 됩니다.
2. Precision(정밀도)
코로나 양성이라고 표시한 사람 중, 실제로 코로나 양성은 몇 명인가?

분자: 실제 코로나 환자로, 코로나 양성 판정된 환자의 수.
분모: 실제로 코로나인지 아닌지에 관계 없이 테스트를 통해 코로나 환자로 분류된 수.
| 예측 - 코로나 양성 | 예측 - 코로나 음성 | ||
| 코로나 양성 | TP - 85 | FN - 15 | 100 |
| 코로나 음성 | FP - 20 | TN - 80 | 100 |
| 105 | 95 | 200 |
정밀도는 양성이라고 예측된 집단에 대한 정확성의 척도입니다. 간단히 말해서 전체 양성 예측 중에서 얼마나 많은 예측이 실제로 양성인지 알려주는 것이죠. 정밀도는 False Positive(Type 1 error)가 False Negatives(Type 2 error)보다 더 위험한 사항인 경우에 유용한 메트릭입니다. 스팸 이메일을 예로 들어보겠습니다.
False Postivie - 스팸 이메일이 아닌데 스팸 이메일이라고 하는 경우.
False Negative - 스팸 이메일인데, 스팸 이메일이 아니라고 하는 경우.
스팸 이메일이 아닌데, 스팸 이메일이라고 하는 False Positive의 경우, 우리는 스팸이 아닌 이메일이 스팸 편지함으로 가게 되는 상황이 발생하게 됩니다.스팸 이메일이지만 아닌 것으로 인식하고 인박스로 들어오는 False Negative의 경우가 차라리 나은거죠. 높은 정밀도를 선택함으로써(스팸 이메일이라고 분류한 것중, 실제 스팸 이메일인 확률이 높을수록) 이메일이 잘못 분류되는 사고를 피할 수 있습니다.
이 외에도, 음악 또는 비디오 추천 시스템, 전자 상거래 웹사이트 등에서는 정밀도가 중요합니다. 잘못된 결과는 고객 이탈로 이어지고 비즈니스에 타격이 될 수 있으니까요.
3. Sensitivity(민감도) = Recall (재현율)
실제 코로나 환자 중, 올바르게 코로나 양성으로 검진한 환자는 몇 명인가?

분자: 실제 코로나 환자로, 코로나 양성 판정된 환자의 수.
분모: 실제 코로나 양성인 환자의 수.
| 예측 - 코로나 양성 | 예측 - 코로나 음성 | ||
| 코로나 양성 | TP - 85 | FN - 15 | 100 |
| 코로나 음성 | FP - 20 | TN - 80 | 100 |
| 105 | 95 | 200 |
Recall은 False Negative(Type 2 error)가 False Positive(Type 1 error)보다 더 위험한 경우에 사용합니다.
False Positive - 코로나가 아닌데 맞다고 하는 경우이므로, 잘못된 경보일 뿐이라고 볼 수 있습니다.
False Negative - 코로나가 맞는데 아니라고 하는 경우로, 매우 위험햘 수 있는 경우입니다.
잘못된 경보를 발령하는지 여부는 중요하지 않지만 실제 양성 사례를 음성으로 판단하게되는 의학적 사례는 매우 위험하겠죠. False Negative 가 낮아질수록, 실제 양성 인구 중에서 양성으로 예측한 경우인 True Postivie 가 높아질 것이고 이는 Recall을 높일 것입니다. 높은 Recall을 선택함으로써 실수로 감염된 사람을 퇴원시켜 건강한 인구와 혼합하여 전염성 바이러스를 퍼뜨리는 것을 막을 수 있습니다.
4. Specificity(특이도)
실제 코로나에 걸리지 않은 건강한 사람 중, 올바르게 코로나 음성을 판정한 환자는 몇 명인가?

분자: 실제 코로나에 걸리지 않은 건강한 사람에게, 코로나 음성으로 판정한 수.
분모: 실제로 코로나에 걸리지 않은 모든 사람.
| 예측 - 코로나 양성 | 예측 - 코로나 음성 | ||
| 코로나 양성 | TP - 85 | FN - 15 | 100 |
| 코로나 음성 | FP - 20 | TN - 80 | 100 |
| 105 | 95 | 200 |
모든 True Negative를 커버하려면 특이성을 선택합니다. 즉, 거짓 경보(False Positive)를 원하지 않는 경우에 해당합니다. 예를 들어 범죄를 저질렀을 때(양성) 즉시 감옥에 가는 재판에서, 죄가 없는 사람이 감옥에 가는 것은 올바르지 않습니다. 여기서 False Postive(죄가 없는데, 죄가 있다고 판별)는 매우 위험하겠죠. 그러므로 이와 같은 상황에서는, True Negative를 구분하는 특이도가 높은 모델을 추구하는 것이 적합합니다.
5. F1 -Score
정밀도와 재현율은 상충관계에 있습니다. 즉, 정밀도를 높이려고 하면 재현율이 떨어지고 그 반대도 마찬가지입니다. 정밀도가 높을수록 데이터 세트의 실제 양성을 의심하는 더 엄격한 잣대를 세우게 되어(High False Negative) 리콜 점수가 감소합니다. 반면에, 재현율을 높일수록 양성을 통과하도록 허용하는데에 느슨해져, 경계 케이스 음성을 양성으로 분류하여(High False Postivie) 정밀도를 감소시킵니다. 이상적으로는 완벽한 모델을 얻기 위해 정밀도와 재현율 메트릭을 모두 최대화하려고 합니다.
그리하여 탄생한 것이 F1 점수인데요. 이는 정밀도와 재현율의 조합 평균으로, 0과 1 사이의 숫자 입니다. 정확도는 대칭 데이터 세트가 있는 경우에(False Negative 와 False Positive의 개수가 비슷함) 사용하기 적합하지만, False Negative와 False Positive의 차이가 아주 큰 비대칭의 데이터 경우에는 F1이 유용합니다.

마지막으로 정리를 해보자면:
- 정확도 값 90%는 라벨 10개 중 1개는 올바르지 않고 9개는 정확함을 의미합니다.
- 정밀도 값 80%는 코로나로 분류된 사람 10명 중 2명이 건강하고 8명이 코로나 환자임을 의미합니다.
- Recall 값이 70%라는 것은 실제 코로나 환자 10명 중 3명은 테스트에서 놓치고 7명은 코로나 환자라는 것을 의미합니다.
- 특이도 값이 60%라는 것은 실제로 건강한 사람 10명 중 4명은 코로나로 잘못 분류되고 6명은 건강하다고 올바르게 분류된다는 의미입니다.
- 정확성은 균형 데이터에 대한 더 나은 지표입니다.
- 정밀도는 False Positive가 훨씬 더 중요할 때 적합합니다.
- Recall은 False Negative가 훨씬 더 중요할 때 적합합니다.
- F1-Score는 불균형 데이터에 대한 더 나은 지표입니다.
'Stats101' 카테고리의 다른 글
| t 검정의 종류와 방법 (0) | 2023.04.21 |
|---|---|
| t-분포(t-Distribution) (0) | 2023.04.19 |
| 표준오차, 표본오차와 신뢰구간 (1) | 2023.04.16 |
| 표본 표준편차에는 왜 n-1을 할까? (0) | 2023.04.12 |
| 분산과 표준편차 (0) | 2023.04.09 |




댓글